PyTorch DataLoaders and Shared Memory
Recently I stumbled upon a weird error while working with some PyTorch code. Here is the minimal reproducible example:
import torch as th
from torch.utils.data import DataLoader, Dataset
class RandomDataset(Dataset):
def __init__(self, size: int) -> None:
super().__init__()
self.size = size
def __len__(self) -> int:
return self.size
def __getitem__(self, index) -> tuple:
return th.randn(10), th.randn(10), th.randn(10), th.randn(10)
def main() -> None:
dataset = RandomDataset(20000)
data_loader = DataLoader(dataset, num_workers=1)
batches = []
for batch in data_loader:
batches.append(batch)
print('Done')
if __name__ == '__main__':
main()
Here we have a RandomDataset class which simply generates a tuple of 4 random tensors size times. In main we create
a data loader with a single worker and iterate over batches appending them to batches list.
If you try to run this, you would get a long stack trace that ends with this error message:
storage = cls._new_shared_fd_cpu(fd, size)
RuntimeError: unable to mmap 4 bytes from file <filename not specified>: Cannot allocate memory (12)
We are told that mmap failed with error code 12 which suggests that we have exceeded some memory limit. As it turns
out, this issue originates in DataLoader itself and is related to how DataLoader workers communicate with the main
process.
DataLoader Multiprocessing
A typical PyTorch training loop would look something like this:
while data_loader is not empty:
fetch a batch from data_loader
model(batch)
optimizer step
This is essentially a sequential process. First, we ask our DataLoader to sample the dataset and collate a batch for us to use. Then, we do a forward and backward passes (which utilize GPU primarily). Once we are finished, we wait for the second batch to load before we can do another forward pass.
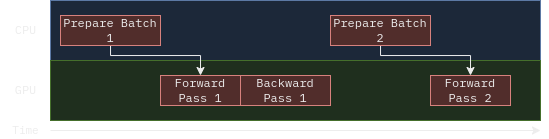
Depending on your Dataset (e.g. loading from slow storage, costly, augmentations, etc), this step can take a long time that GPU will spend idling. Since data can usually be loaded and preprocessed in parallel, a natural idea is to utilize some sort of parallelism inside the data loader. Moreover, with parallelism, we can actually pre-fetch the next batch while we are waiting for the model to finish.
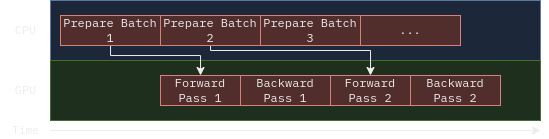
This is exactly what PyTorch DataLoader does under the hood.
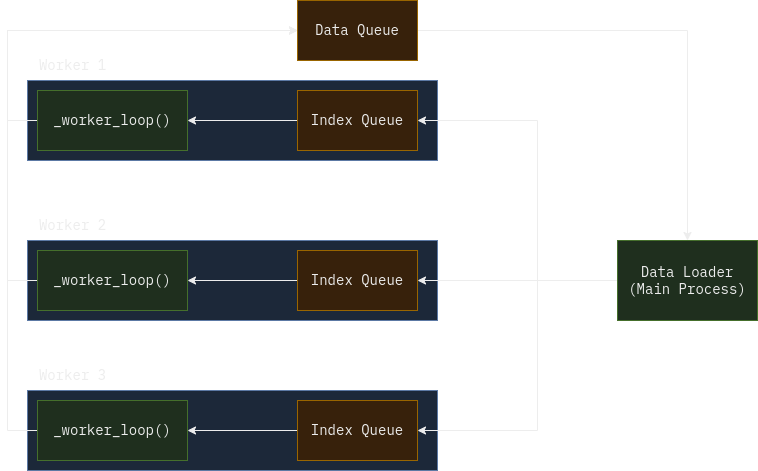
PyTorch uses a simple work-queue pattern. DataLoader spawns several worker processes and creates
an index queue for each worker. When you iterate over the data loader, it splits dataset indices
among the workers and distributes them to their index queues. Workers then pull the indices and do the actual
sampling (e.g. dataset.__getitem__) with given indices and send the result to the common data queue,
which is then read back by the data loader and returned to us.
Due to GIL, Python can’t have proper threading parallelism, so PyTorch has to resolve to processes. Using processes avoids GIL, though introduces some other complications like a need for IPC.
Linux (and other operating systems, but I’ll focus on Linux here) has memory protection mechanisms that were
put in place to prevent processes from reading and mutating each other’s memory. This is somewhat of a necessity due
to security and stability reasons, though it is inconvenient when we actually want two processes to share data (like in this case).
The way around this is to use IPC (Inter-Process Communication) mechanisms. Data and Index queues in the diagram
above are implemented using modified Python’s multithreading.Queue object, which is essentially a Unix
pipe. They are easy to work with and thread-safe, which is convenient.
However, suppose a worker process samples the dataset which allocates a new tensor. Tensor is allocated inside the worker process memory and to transfer it to the main process you would need to push the entire tensor through the data queue pipe which is slow and inefficient.
For sharing tensors between processes, PyTorch uses a special kind of IPC called shared memory. Shared memory is essentially a memory region that can be accessed by several processes at the same time. Unlike pipes, once a shared memory region is mapped, the kernel is not involved with data transfers which means bytes can be copied more efficiently.
Shared Tensors
So when a tensor is put inside the data queue by a worker process, PyTorch creates a new shared memory region and places tensor data
in it. What gets sent through the pipe is actually a file descriptor to the shared memory region. This happens inside reduce_storage function in
torch/multiprocessing/reductions.py.
reduce_storage is called when a tensor is pushed into a queue (see torch/multiprocessing/queue.py).
def reduce_storage(storage):
...
fd, size = storage._share_fd_cpu_()
df = multiprocessing.reduction.DupFd(fd)
cache_key = fd_id(fd)
metadata = (df, size)
rebuild = rebuild_storage_fd # type: ignore[assignment]
...
storage._share_fd_cpu_() is what actually places the tensor data into shared memory. It is bound to
THPStorage_shareFd
function which creates new storage using MapAllocator
class with ALLOCATOR_MAPPED_SHARED flag which instructs MapAllocator to create a new shared memory region.
...
#ifdef HAVE_SHM_OPEN
if((fd = shm_open(filename_.c_str(), flags, (mode_t)0600)) == -1) {
TORCH_CHECK(false, "unable to open shared memory object <", filename_, "> in read-write mode: ", strerror(errno), " (", errno, ")");
}
#else
...
shm_open is what actually creates a shared memory segment. In the same function mmap is used to map the newly
created segment:
if (flags_ & (ALLOCATOR_MAPPED_SHARED | ALLOCATOR_MAPPED_SHAREDMEM)) {
base_ptr_ = mmap(nullptr, size_, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);
}
Then, the pointer to the region is used to create a new Storage and the original tensor is simply copied into it:
at::Storage new_storage(at::new_shm_fd_storage(storage.nbytes()));
{
// Copying into shared memory can be slow, so release the GIL
pybind11::gil_scoped_release no_gil;
// Copy data from old storage into the new one
at::storage_copy(new_storage, storage);
}
Thanks to PyTorch, we can actually access this API from Python. Tensor class implements two related methods:
memory_share_()
(which is equivalent to _share_fd_cpu_ for cpu tensors) and
is_shared().
Let’s play around with them a little. On Linux, shared memory can be inspected using lsof /dev/shm command.
PyTorch uses torch_ prefix with its tensors. Let’s try to create a few shared tensors and see what happens:
import torch as th
x = th.tensor([1,2,3])
x.data_ptr()
Out[4]: 94350617509440
x.is_shared()
Out[5]: False
x.share_memory_()
Out[6]: tensor([1, 2, 3])
x.is_shared()
Out[7]: True
x.data_ptr()
Out[8]: 140618151415808
We first create a tensor x. data_ptr() allows us to see the address where the actual data is stored.
We call share_memory_() method and data_ptr() returns a new address. Running lsof /dev/shm | grep torch:
python3.1 2149720 xxx DEL REG 0,26 170061957 /dev/shm/torch_2149720_1191275662_0
We can see that python process created a new shmem region named torch_2149720_1191275662_0 which is our actual
tensor.
Shared Memory Limits
That was a lot of information to handle, though we can finally return to the initial code snippet and identify the problem. We now know that tensors that were sent through the queue are shared, let’s check it:
...
for batch in data_loader:
print(batch[0].is_shared()) # True
batches.append(batch)
...
Tensors arrive shared by default. This is a problem here because we save batches in batches list,
which means that batch tensor is not garbage collected when it goes out of scope and the shared memory region
remains alive. Shared memory is not unlimited and once we hit the limit we get the error from _new_shared_fd_cpu
function which we saw earlier.
storage = cls._new_shared_fd_cpu(fd, size)
RuntimeError: unable to mmap 4 bytes from file <filename not specified>: Cannot allocate memory (12)
There are 2 ways to solve this problem, the easiest one is to set num_workers to 0. This way everything happens inside
the main process and there’s no need for IPC.
A better solution would be to move arriving tensors from shared memory into main process memory. This can be achieved
by a simple clone().
...
for batch in data_loader:
print(batch.is_shared()) # True
batches.append((b.clone() for b in batch))
...
This way, original tensor data that lives in shared memory gets garbage collected as we are cloning it, and no references are stored.